| species | body_wt | brain_wt | |
|---|---|---|---|
| 0 | Africanelephant | 6654.000 | 5712.0 |
| 1 | Africangiantpouchedrat | 1.000 | 6.6 |
| 2 | ArcticFox | 3.385 | 44.5 |
Data science lifecycle
PSTAT100 Spring 2023
Invalid Date
What’s data science?
Data science is a term of art encompassing a wide range of activities that involve uncovering insights from quantitative information.
People that refer to themselves as data scientists typically combine specific interests (“domain knowledge”, e.g., biology) with computation, mathematics, and statistics and probability to contribute to knowledge in their communities.
- Intersectional in nature
- No singular disciplinary background among practitioners
Data science lifecycle
Data science lifecycle: an end-to-end process resulting in a data analysis product
- Question formulation
- Data collection and cleaning
- Exploration
- Analysis
These form a cycle in the sense that the steps are iterated for question refinement and futher discovery.
Data science lifecylce
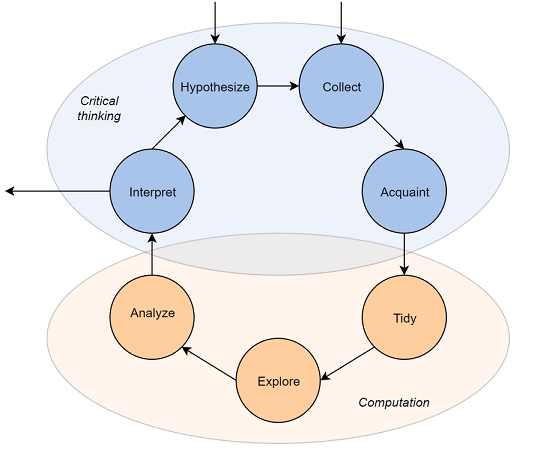
The point isn’t really the exact steps, but rather the notion of an iterative process.
Starting with a question
The scaling of brains with bodies is thought to contain clues about evolutionary patterns pertaining to intelligence.
There are lots of datasets out there with brain and body weight measurements, so let’s consider the question:
What is the relationship between an animal’s brain and body weight?
Data acquisition
From Allison et al. 1976, average body and brain weights for 62 mammals.
Units of measurement
- body weight in kilograms
- brain weight in grams
Data assessment
How well-matched is the data to our question?
- Mammals only (no birds, fish, reptiles, etc.)
- Species are those for which convenient specimens were available
- Averages across specimens are reported (‘aggregated’ data)
What do you think? Take a moment to discuss with your neighbor.
Data assessment
Based on the great points you just made, we really only stand to learn something about this particular sample of animals.
In other words, no inference is possible.
Do you think the data are still useful?
Inpection
This dataset is already impeccably neat: each row is an observation for some species of mammal, and the columns are the two variables (average weight).
So no tidying needed – we’ll just check the dimensions and see if any values are missing.
Exploration
Visualization is usually a good starting point for exploring data.
Notice the apparent density of points near \((0, 0)\) – that suggests we shouldn’t look for a relationship on the scale of kg/g.
Exploration
A simple transformation of the axes reveals a clearer pattern.
Analysis
The plot shows us that there’s a roughly linear relationship on the log scale:
\[\log(\text{brain}) = \alpha \log(\text{body}) + c\]
So what does that mean in terms of brain and body weights? A little algebra and we have a “power law”:
\[(\text{brain}) \propto (\text{body})^\alpha\]
Check your understanding: what’s the proportionality constant?
Interpretation
So it appears that the brain-body scaling is well-described by a power law:
among selected specimens of these 62 species of mammal, species average brain weight is approximately proportional to a power of species average body weight
Notice that I did not say:
- animals’ brains are proportional to a power of their bodies
- among these 62 mammals, average brain weight is approximately proportional to a power of average body weight
Question refinement
We can now ask further, more specific questions:
Do other types of animals exhibit the same power law relationship?
To investigate, we need richer data.
(More) data acquisition
A number of authors have compiled and published ‘meta-analysis’ datasets by combining the results of multiple studies.
Below we’ll import a few of these for three different animal classes.
Data assessment
Where does this data come from? It’s kind of a convenience sample of scientific data:
- Multiple studies \(\rightarrow\) possibly different sampling and measurement protocols
- Criteria for inclusion unknown \(\rightarrow\) probably neither comprehensive nor representative of all such measurements taken
So these data, while richer, are still relatively narrow in terms of generalizability.
A comment on scope of inference
These data don’t support general inferences (e.g., to all animals, all mammals, etc.) because they weren’t collected for the purpose to which we’re putting them.
Usually, if data are not collected for the explicit purpose of the question you’re trying to answer, they won’t constitute a representative sample.
Tidying
Back to the task at hand, in order to comine the datasets one must:
- Select columns of interest;
- Put in consistent order;
- Give consistent names;
- Concatenate row-wise.
We’ll skip the details for now.
Inspection
This dataset has quite a lot of missing brain weight measurements: many of the studies combined to form these datasets did not include that particular measurement.
Exploration
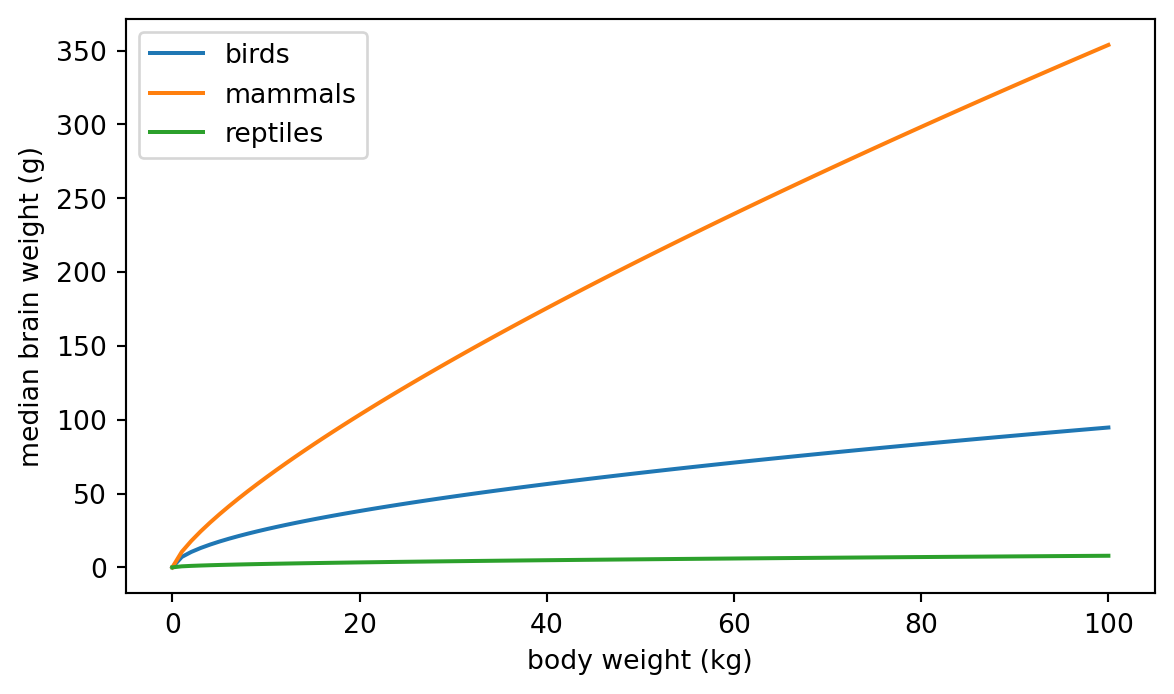
Focusing on the nonmissing values, we see the same power law relationship but with different proportionality constants and exponents for the three classes of animals.
Analysis
So we might hypothesize that:
\[ (\text{brain}) = \beta_1(\text{body})^{\alpha_1} \qquad \text{(mammal)} \\ (\text{brain}) = \beta_2(\text{body})^{\alpha_2} \qquad \text{(reptile)} \\ (\text{brain}) = \beta_3(\text{body})^{\alpha_3} \qquad \text{(bird)} \\ \beta_i \neq \beta_j, \alpha_i \neq \alpha_j \quad \text{for } i \neq j \]
Interpretation
It seems that the average brain and body weights of the birds, mammals, and reptiles measured in these studies exhibit distinct power law relationships.
What would you investigate next?
- Correlates of body weight?
- Adjust for lifespan, habitat, predation, etc.?
- Estimate the \(\alpha_i\)’s and \(\beta_i\)’s?
- Predict brain weights for unobserved species?
- Something else?
A comment
Notice that I did not mention the word ‘model’ anywhere!
This was intentional – it is a common misconception that analyzing data always involves fitting models.
- Models are not not always necessary or appropriate
- You can learn a lot from exploratory techniques
- Models approximate specific kinds of relationships in data
- Exploratory analysis can reveal unexpected structure
But if we did want to fit a model…
\((\text{brain}) = \beta_j(\text{body})^{\alpha_j} \quad \text{animal class } j = 1, 2, 3\)
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
| Bird | -1.9574 | 0.040 | -49.118 | 0.000 | -2.036 | -1.879 |
| Mammal | -2.9391 | 0.029 | -100.061 | 0.000 | -2.997 | -2.882 |
| Reptile | -4.0335 | 0.083 | -48.577 | 0.000 | -4.196 | -3.871 |
| log.body.bird | 0.5653 | 0.008 | 66.566 | 0.000 | 0.549 | 0.582 |
| log.body.mammal | 0.7651 | 0.004 | 191.544 | 0.000 | 0.757 | 0.773 |
| log.body.reptile | 0.5293 | 0.017 | 31.375 | 0.000 | 0.496 | 0.562 |
Model limitations
Back to the issue of representativeness:
- shouldn’t use this model for inferences
- might not be reliable for prediction either
- but does capture/convey some suggestive comparisons
So, just be careful with interpretation of results:
“For this particular collection of specimens, we estimated…”
Zooming out
This example illustrates the aspects of the lifecylce we’ll cover in this class:
- data retrieval and import
- tidying and transformation
- visualization
- exploratory analysis
- modeling
We’ll address these topics in sequence.
Next week
- Tabular data structure
- Data semantics
- Tidy data
- Transformations of tabular data
- Aggregation and grouping