np.random.seed(41021)
# proportion of fraudlent requests
true_prop = 0.009
# generate population of voters who had unreturned mail ballots
N = 150000
population = pd.DataFrame(data = {'requested': np.ones(N)})
# how many didn't request mail ballots?
num_nrequest = round(N*true_prop) - 1
# set the 'requested' indicator to zero for the top chunk of data
population.iloc[0:num_nrequest, 0] = 0Case study on sampling and missingness
PSTAT100 Spring 2023
Invalid Date
The Miller case
On November 21, 2020, a professor at Williams College, Steven Miller, filed an affidavit alleging that an analysis of phone surveys showed that among registered republican voters in PA:
- ~40K mail ballots were fraudlently requested;
- ~48K mail ballots were not counted.
“President Donald J. Trump amplified the statement in a tweet, the Chairman of the Federal Elections Commission (FEC) referenced the statement as indicative of fraud, and a conservative group prominently featured it in a legal brief seeking to overturn the Pennsylvania election results.” (Samuel Wolf, Williams Record, 11/25/20)
The Miller affidavit was criticized by statisticians as incorrect, irresponsible, and unethical.
We’ll focus on the first claim.
The calculation
On a purely mathematical level, the calculations were straightforward.
- \(N = 165,412\) mail ballots were requested by registered republicans but not returned.
- Phone surveys of \(n = 2250\) of those voters identified \(556\) who claimed not to request ballots.
\[ \text{sample proportion} \times \text{population size} = \frac{556}{2250} \times 165,412 = 40,875 \]
The flawed assumption
The key issue was a single flawed assumption:
“The analysis is predicated on the assumption that the responders are a representative sample of the population of registered Republicans in Pennsylvania for whom a mail-in ballot was requested but not counted, and responded accurately to the questions during the phone calls.”” (Miller affidavit)
Essentially, two critical mistakes were made in the analysis:
- Failure to critically assess the sampling design and scope of inference.
- Ignoring missing data.
Miller is a number theorist, not a trained survey statistician, so on some level his mistakes were understandable, but they did a lot of damage. He issued an apology in short order.
The survey
There were 165,412 unreturned mail ballots requested by registered republicans in PA.
Those voters were surveyed by phone by Matt Braynard’s private firm External Affairs on behalf of the Voter Integrity Fund.
We don’t really know how they obtained and selected phone numbers or exactly what the survey procedure was, but here’s what we do know:
- ~23K individuals were called on Nov. 9-10.
- The ~2.5K who answered were asked if they were the registered voter or a family member.
- If they said yes, they were asked if they requested a ballot.
- Those who requested a ballot were asked if they mailed it.
Potential sources of bias
There are several obvious sampling problems.
- Undisclosed selection mechanism
- Narrow snapshot in time; 9th and 10th were a Monday and Tuesday, less likely to reach workers.
- Unknown at this time whether mail ballots were ultimately returned and counted or not by this time, so the frame doesn’t align with the population.
There are also some obvious measurement problems.
- Family members could answer on behalf of one another and may give incorrect answers.
- Respondents may not be aware that they requested a ballot, as you don’t have to file an explicit request in Pennsylvania (there’s a checkbox on the voter registration form).
- Voters who believed they did not request a ballot were not asked if they recieved and/or returned one.
Survey schematic
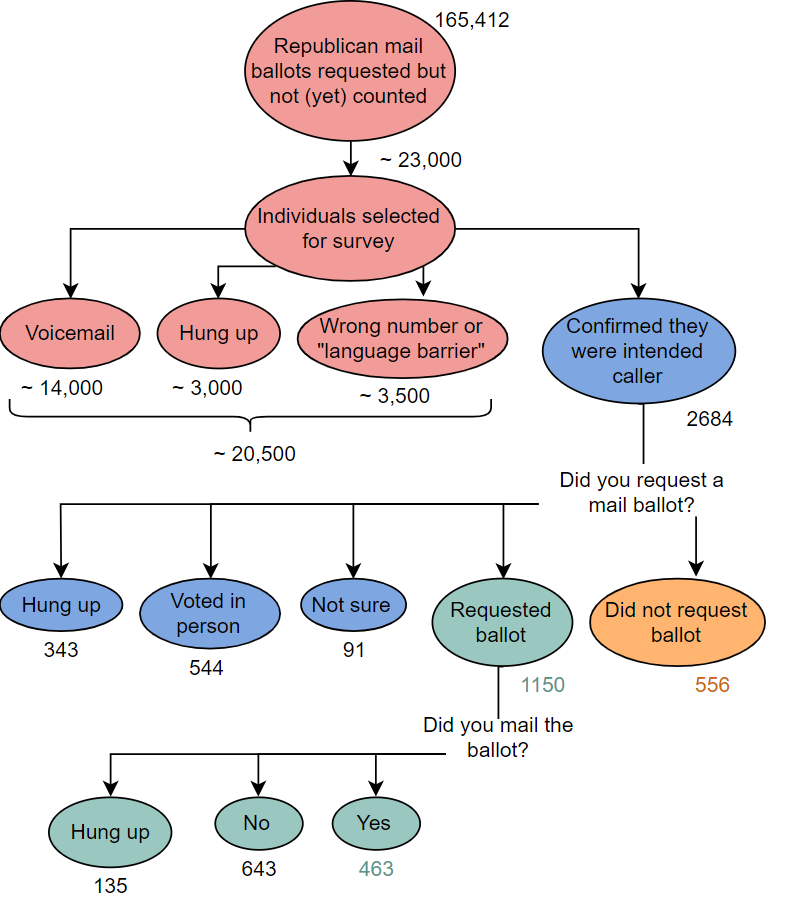
Sampling design
Population: republicans registered to vote in PA who had unreturned mail ballots issued
Sampling frame: unknown; source of phone numbers unspecified.
Sample: 2684 registered republicans or family members of registered repbulicans who had a mail ballot officially requested in PA and answered survey calls on Nov. 9 or 10.
Sampling mechanism: nonrandom; depends on availability during calling hours on Monday and Tuesday, language spoken, and willingness to talk.
This is not a representative sample of any meaningful population.
Missingness
Respondents hung up at every stage of the survey. This is not at random – individuals who do not believe there were any irregularities in mail ballots are less likely to talk or continue talking.
So data are MNAR and over-represent people more likely to claim they never requested a ballot.
The analysis
Miller first calculated the proportion of respondents who reported not requesting ballots among those who did not hang up after the first question.
\[ \left(\frac{556}{1150 + 556 + 544}\right) = 0.2471 \]
Then he extrapolated that the estimated number of fraudulent requests was:
\[ 0.2471 \times 165,412 = 40,875 \]
The two main problems with this are:
- nonrandom sampling \(\Longrightarrow\) no scope of inference
- no adjustment for nonresponse (i.e., missing data)
Simulation
It’s not too tricky to envision sources of bias that would affect the results.
Assume that:
- respondents all know whether they actually requested a ballot
- respondents tell the truth
- respondents who didn’t request a ballot are more likely to be reached
- respondents who did request a ballot are more likely to hang up during the interview
Then we can show through a simple simulation that an actual fraud rate of under 1% will be estimated at over 20% almost all the time.
Simulated population
First let’s generate a population of 150K voters.
Simulated sample
Then let’s introduce sampling weights based on the conditional probability that an individual will talk with the interviewer given whether they requested a ballot or not.
# assume respondents tell the truth
p_request = 1 - true_prop
p_nrequest = true_prop
# non-requesters are more likely to talk by this factor
talk_factor = 15
# observed response rate
p_talk = 0.09
# conditional response rates
p_talk_request = p_talk/(p_request + talk_factor*p_nrequest)
p_talk_nrequest = talk_factor*p_talk_request
# append conditional response rates as weights
population.loc[population.requested == 1, 'sample_weight'] = p_talk_request
population.loc[population.requested == 0, 'sample_weight'] = p_talk_nrequest
# draw weighted sample
np.random.seed(41923)
samp_complete = population.sample(n = 2500, replace = False, weights = 'sample_weight')Think of the weights as conditional response rates.
Simulated missing mechanism
Then let’s introduce missing values at different rates for respondents who requested a ballot and respondents who didn’t.
# requesters are more likely to hang up by this factor
missing_factor = 10
# overall nonresponse rate
p_missing = 0.6
# conditional probabilities of missing given request status
p_missing_nrequest = p_missing/(p_nrequest + missing_factor*p_request)
p_missing_request = missing_factor*p_missing_nrequest
# append missingness weights to sample
samp_complete.loc[samp_complete.requested == 1, 'missing_weight'] = p_missing_request
samp_complete.loc[samp_complete.requested == 0, 'missing_weight'] = p_missing_nrequest
# make a copy of the sample
samp_incomplete = samp_complete.copy()
# input missing values at random
np.random.seed(41923)
samp_incomplete['missing'] = np.random.binomial(n = 1, p = samp_incomplete.missing_weight.values)
samp_incomplete.loc[samp_incomplete.missing == 1, 'requested'] = float('nan')Simulated result
If we then drop all the missing values and calculate the proportion of respondents who didn’t request a ballot, we get:
So Miller’s result is expected if the sampling and missing mechanisms introduce bias, even if the true rate of fraudulent requests is under 1% – on the order of 1,000 ballots.
In class activity
Open the notebook and try it for yourself.
Some comments:
- I chose these settings specifically to replicate the \(24\%\) estimate.
- I inflated the nonresponse rate relative to the survey to achieve this.
- The simulation is not an exact model of the actual survey; the survey has other sources of bias.
- You should try inputting settings that you think are realistic. You’ll still see significant bias.
Professional ethics
The American Statistical Association publishes ethical guidelines for statistical practice. The Miller case violated a large number of these, most prominently, that an ethical practitioner:
Reports the sources and assessed adequacy of the data, accounts for all data considered in a study, and explains the sample(s) actually used.
In publications and reports, conveys the findings in ways that are both honest and meaningful to the user/reader. This includes tables, models, and graphics.
In publications or testimony, identifies the ultimate financial sponsor of the study, the stated purpose, and the intended use of the study results.
When reporting analyses of volunteer data or other data that may not be representative of a defined population, includes appropriate disclaimers and, if used, appropriate weighting.