| PM25_mean | City | State | Year | |
|---|---|---|---|---|
| 0 | 8.6 | Aberdeen | SD | 2000 |
| 1 | 8.6 | Aberdeen | SD | 2001 |
| 2 | 7.9 | Aberdeen | SD | 2002 |
| 3 | 8.4 | Aberdeen | SD | 2003 |
Exploratory analysis and density estimation
PSTAT100 Spring 2023
Invalid Date
Announcements
- No assignment posted this week
- No lab next week
This week: EDA and smoothing
- What is exploratory data analysis (EDA)?
- The role of data: information or evidence?
- Exploratory vs. confirmatory analysis
- Essential exploratory questions: variation and co-variation
- Smoothing
- Kernel density estimation (KDE)
- LOESS
EDA
The term and spirit of exploratory data analysis (EDA) is attributed to John Tukey, whose philosophically-leaning work in statistics in the 1960’s and 1970’s stressed the need for more data-driven methods.
For a long time I have thought I was a statistician, interested in inferences from the particular to the general … All in all, I have come to feel that my central interest is in data analysis [which] is a larger and more varied field than inference. (Tukey, 1962)
EDA is an initial stage of non-inferential and largely model-free analysis aiming at understanding the structure, patterns, and particularities present in a dataset.
Data as evidence
Experimental data usually serve the role of evidence for or against prespecified hypotheses.
\[ \text{hypothesis} \longrightarrow \text{data} \longrightarrow \text{inference} \]
For example, in vaccine efficacy trials, trial data are collected precisely to affirm or refute the hypothesis of no effect:
| Vaccine group | Placebo group |
|---|---|
| 11 cases | 185 cases |
\(\hat{P}(\text{case is in the vaccine group}) = 0.056 \quad\Longrightarrow\quad \text{evidence of effect}\)
Data as information
By contrast, observational data more often serve the role of information about some phenomenon.
For example, a secondary trial target might is to assess saftey by gathering observational data on side effects; for this there is no hypothesis.
EDA then CDA
The picture that most practitioners have of modern data science is that EDA precedes confirmatory data analysis (CDA).
- EDA is used to generate hypotheses or formulate a model based on patterns in the data
- CDA, consisting of model specification and estimation, is used for inference and/or prediction
Aside: Historically, statistics has focused on CDA – and therefore a lot of your PSTAT coursework does, too.
Essential exploratory questions
When you ask a question, the question focuses your attention on a specific part of your dataset and helps you decide which graphs, models, or transformations to make.
There are two basic kinds of questions that are always useful:
- What type of variation occurs within variables?
- What type of covariation occurs between variables?
Variation in one variable
Variation in data is the tendency of values to change from measurement to measurement.
For example, the following observations from your mini project data are around 8 \(\mu g/m^3\), but each one is different.
What does it mean to ask what ‘type’ of variation there is in this data?
Questions about variation
There aren’t exact types of variation, but here are some useful questions:
(Common) Which values are most common?
(Rare) Which values are rare?
(Spread) How spread out are the values and how are they spread out?
(Shape) Are values spread out evenly or irregularly?
These questions often lead the way to more focused ones.
Air quality
The following histogram shows the distribution of PM 2.5 concentrations across all 200 cities and 20 years.
It shows several statistical properties of the data related to variation:
The common values have the highest bars – values between roughly 6 and 14.
Values under 4 and over 18 are rare, accounting for under 5% of the data.
Values are concentrated between 4 and 18, but are spread from 2 to 52.
The shape is pretty even but a little more spread out to the right (“right skew”).
Question refinement
New question: The national standard is 12 micrograms per cubic meter. Over 1,000 measurements exceeded this. Was it just a few cities, or more widespread?
Many cities exceeded the standard at some point in time: over 70% of the cities in the dataset. So it was more widespread, but these were the worst:
City State
Hanford-Corcoran CA 20
Visalia-Porterville CA 20
Fresno CA 19
Bakersfield CA 18
Name: Years exceeding standard, dtype: int64Further questions
How many cities exceed the benchmark each year? Does this change from year to year?
There are a lot of years and it’s hard to see anything with all the overlapping bars.
- Remember the rule? Don’t stack histograms.
- Use density plots instead.
Further questions
Visually, it’s a lot easier to distinguish overlapping lines than overlapping bars. Smoothing out the histogram produces this:
This shows that both the variation in PM 2.5 and the typical values are diminishing over time.
- suggests fewer cities exceed the EPA standard (12 \(\mu g/m^3\)) over time
- a few outliers in some early year
- not the best presentation graphic, but useful exploratory graphic
Further questions
This gets the message across better.
And here are those outlying values:
| PM25_mean | City | State | Year | |
|---|---|---|---|---|
| 1984 | 51.2 | Fairbanks | AK | 2004 |
| 1985 | 31.3 | Fairbanks | AK | 2005 |
Density estimates
All of the above has amounted to exploration of the distribution of PM 2.5 values across years and cities.
Density estimates provide smooth approximations of distributions:
These are useful tools for answering questions about variation. Relative to the histogram:
- Easier to see the shape, spread, and typical values quickly.
- Easier to compare multiple distributions.
Histograms and probability densities
From 120A, a probability density/mass function has two properties:
- Nonnegative: \(f(x) \geq 0\) for every \(x \in \mathbb{R}\).
- Sums/integrates to one: \(\int_\mathbb{R} f(x) dx = 1\) or \(\sum_{x \in \mathbb{R}} f(x) = 1\)
Histograms are almost proper density functions: they satisfy (1) but not (2).
A preliminary: indicator functions
In what follows we’re going to express the histogram mathematically as a function of data values.
This will require the use of indicator functions, which are simply functions that are 1 or 0 depending on a condition. They are denoted like this:
\[ \mathbf{1}\{\text{condition}\} = \begin{cases} 1 &\text{ if condition is true} \\ 0 &\text{ if condition is false} \end{cases} \]
The sum of an indicator gives a count of how many times the condition is met:
\[ \sum_i \mathbf{1}\{x_i > 0\} = \#\text{ of values that are positive} \]
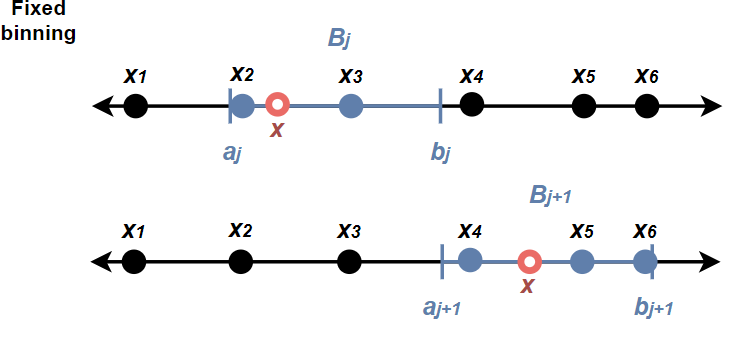
Count scale histograms
When the bar height is a count of the number of observations in each bin, the histogram is on the count scale.
More precisely, if the values are \(x_1, \dots, x_n\), then the height of the bar for the \(j\)th bin \(B_j = (a_j, b_j]\) is: \[ \text{height}_j = \sum_{i = 1}^n \mathbf{1}\{x_i \in B_j\} \]
Bad for comparisons: the bar heights incomparable in scale whenever the bin widths and/or sample sizes differ.
Density scale histograms
A fix that ensures comparability of scale for any two histograms is to normalize heights by bin width \(b\) and sample size \(n\).
\[ \text{height}_j = \color{red}{\frac{1}{nb}} \sum_{i = 1}^n \mathbf{1}\{x_i \in B_j\} \quad\text{where}\quad b = b_j - a_j \]
Now the area under the histogram is \(\sum_j b \times \text{height}_j = 1\), so we call this a density scale histogram, because it is a valid probability density.
Smoothing
Kernel density estimates are local smoothings of the density scale histogram.
This can be seen by comparing the type of smooth curve we saw earlier with the density scale histogram.
How KDE works
Technically, KDE is a convolution filtering. We can try to understand it in more intuitive terms by developing the idea constructively from the density histogram in two steps.
- Do locally adaptive binning
- Replace counting by weighted aggregation
The histogram as a step function
The value (height) of the density scale histogram at an arbitrary point \(\color{red}{x}\) is \[ \text{hist}(\color{red}{x}) = \frac{1}{nb} \sum_{i = 1}^n \sum_{j} \mathbf{1}\{\color{red}{x} \in B_j\} \mathbf{1}\{x_i \in B_j\} \]
Here’s what those indicators do:
\[ \mathbf{1}\{\color{red}{x} \in B_j\} \quad \text{finds the right bin}\;,\quad \mathbf{1}\{x_i \in B_j\} \quad \text{picks out the data points in the bin} \]
A ‘local’ histogram
One could do a ‘moving window’ binning by allowing the height at \(\color{red}{x}\) to be a normalization of the count in a neighborhood of \(x\) of width \(b\) rather than in one of a fixed set of bins:
\[ \text{hist}_\text{local}(\color{red}{x}) = \frac{1}{nb} \sum_{i = 1}^n \mathbf{1}\left\{|x_i - \color{red}{x}| < \frac{b}{2}\right\} \]
Let’s call this a local histogram, because the height at any point \(\color{red}{x}\) is determined relative to the exact location of \(\color{red}{x}\).
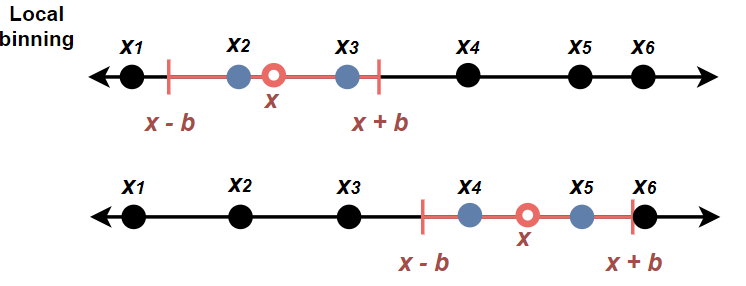
Drawing a local histogram
\[ \text{hist}_\text{local}(\color{red}{x}) = \frac{1}{nb} \sum_{i = 1}^n \mathbf{1}\left\{|x_i - \color{red}{x}| < \frac{b}{2}\right\} \]
PM 2.5 data
Here’s what that would look like with \(b = 1\) for the air quality data:
PM 2.5 data
Zooming in reveals that this is still a step function:
The kernel function
The local histogram is in fact a density estimate with a uniform ‘kernel’: \[ \text{hist}_\text{local}(\color{red}{x}) = \frac{1}{n} \sum_{i = 1}^n \underbrace{\frac{1}{b}\mathbf{1}\left\{|x_i - \color{red}{x}| < \frac{b}{2}\right\}}_\text{kernel function} \]
- uniform because the kernel function is constant about \(x\)
- when \(x_1, \dots, x_n\) are a random sample, this is an estimate of the population denisty
Gaussian KDE
Replacing the uniform kernel with a Gaussian kernel yields a smooth density estimate: \[ \hat{f}(\color{red}{x}) = \frac{1}{n} \sum_{i = 1}^n \frac{1}{b}\varphi\left(\frac{x_i - \color{red}{x}}{b}\right) \]
- \(\varphi\) is the standard Gaussian density \(\varphi(z) = \frac{1}{\sqrt{2\pi}}\exp\left\{- \frac{z^2}{2}\right\}\)
- \(b\) is the smoothing ‘bandwidth’
In effect, the KDE curve at any point \(\color{red}{x}\) is a weighted aggregation of all the data with weights proportional to their distance from \(\color{red}{x}\).
Smoothing bandwidth
The bandwidth parameter \(b\) controls how wiggly the KDE curve is.
The choice of smoothing bandwidth can change the visual impression.
- too much smoothing can obscure outliers and multiple modes
- too little smoothing can misleadingly overemphasize sample artefacts
Other kernels
In general, a KDE can be computed with any appropriately normalized nonnegative kernel function \(K_b(\cdot)\).
\[ \hat{f}_{K_b}(\color{red}{x}) = \frac{1}{n} \sum_{i = 1}^n K_b\left(x_i - \color{red}{x}\right) \]
Other common kernel functions include:
- triangular kernel \(K(z) = 1 - |z|\)
- parabolic kernel \(K(z) \propto 1 - z^2\)
- cosine kernel \(K(z) \propto \cos\left(\frac{\pi z}{2}\right)\)
- circular density \(K(z) \propto \exp\left\{k\cos(z)\right\}\)
- any symmetric continuous probability density function
KDE in higher dimensions
Usually for multivariate data it’s easier to work with conditional distributions, but KDE can be generalized to estimating joint densities in \(p\) dimensions:
\[ \hat{f}_K (\mathbf{x}) = \frac{1}{n} \sum_i |\mathbf{B}|^{-1/2} K \left(\mathbf{B^{-1/2}}(\mathbf{x} - \mathbf{x}_i)\right) \]
- \(\mathbf{x}\in\mathbb{R}^p\) is a \(p\)-dimensional vector
- \(K:\mathbb{R}^p \rightarrow \mathbb{R}\) is a nonnegative kernel function
- \(B\) is a \(p\times p\) matrix of bandwidth parameters
The usual approach is to decorrelate the variates and apply a product kernel \(K(\mathbf{z}) = K_1(z_1)K_2(z_2)\cdots K_p(z_p)\) with separate bandwidths for each dimension.
Bivariate example


Does race time seem correlated with runner’s age?