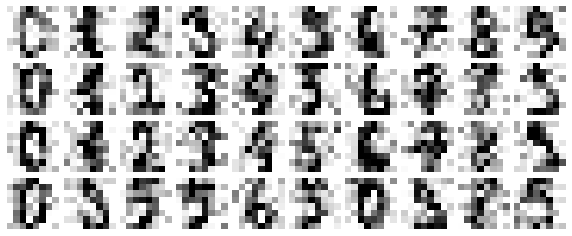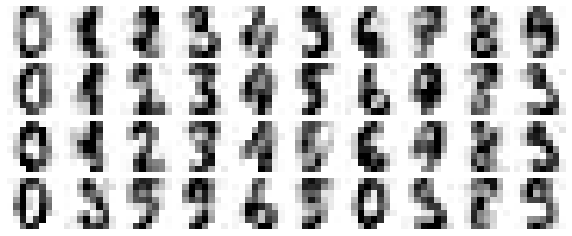Most implementations use SVD, so don’t be surprised if you see this more often than eigendecomposition.
PCA in the low-dimensional setting
Let’s consider finding the principal components for \(p = 2\) variables. Consider: \[
\mathbf{X} = [\mathbf{x}_1 \; \mathbf{x}_2] \qquad\text{where}\qquad \mathbf{x}_1 = \text{social index} \;\text{and}\; \mathbf{x}_2 = \text{economic index}
\]
To get the correlation matrix, first compute \(\mathbf{Z} = \left\{\frac{x_i - \bar{x}}{s_x}\right\}\).
Code
# scatterplot of unscaled dataraw = alt.Chart(x_mx).mark_point(opacity =0.1, color ='black').encode( x = alt.X('Social_Domain', scale = alt.Scale(domain = [0.1, 0.8])), y = alt.Y('Econ_Domain', scale = alt.Scale(domain = [0.1, 0.8]))).properties(width =200, height =200, title ='original data (X)')# mean vectormean = alt.Chart( pd.DataFrame(x_mx.mean()).transpose()).mark_circle(color ='red', size =100).encode( x = alt.X('Social_Domain'), y = alt.Y('Econ_Domain'))# scatterplot of centered and scaled datacentered = alt.Chart(z_mx).mark_point(opacity =0.1, color ='black').encode( x = alt.X('Social_Domain'), y = alt.Y('Econ_Domain')).properties(width =200, height =200, title ='centered and scaled (Z)')# mean vectormean_ctr = alt.Chart( pd.DataFrame(z_mx.mean()).transpose()).mark_circle(color ='red', size =100).encode( x = alt.X('Social_Domain'), y = alt.Y('Econ_Domain'))# lines at zeroaxbase = alt.Chart( pd.DataFrame({'Social_Domain': 0, 'Econ_Domain': 0}, index = [0]))ax1 = axbase.mark_rule().encode(x ='Social_Domain')ax2 = axbase.mark_rule().encode(y ='Econ_Domain')#layerfig1 = (raw + mean) | (centered + mean_ctr + ax1 + ax2)fig1.configure_axis( domain =False, labelFontSize =14, titleFontSize =16 ).configure_title( fontSize =16 )
PCA in the low-dimensional setting
Now we’ll compute the eigendecomposition.
Code
x_mx = x_mx.iloc[:, 0:2]z_mx = z_mx.iloc[:, 0:2]# compute correlation mxr_mx = z_mx.transpose().dot(z_mx)/(len(z_mx) -1)# eigendecompositionr_eig = linalg.eig(r_mx.values)# show PC directionsdirections = pd.DataFrame(r_eig[1], columns = ['PC1_Direction', 'PC2_Direction'], index = r_mx.columns)directions
PC1_Direction
PC2_Direction
Econ_Domain
0.707107
-0.707107
Social_Domain
0.707107
0.707107
The ‘principal component directions’ are simply the eigenvectors.
PCA in the low-dimensional setting
Let’s plot the principal component directions on the centered and scaled data.
Code
# store directions as dataframe for plottingdirection_df = pd.DataFrame( np.vstack([np.zeros(2), r_eig[1][:, 0], np.zeros(2), r_eig[1][:, 1]]), columns = ['Econ_Domain', 'Social_Domain']).join( pd.Series(np.repeat(['PC1', 'PC2'], 2), name ='PC direction'))# plot directions as vectorseigenbasis = alt.Chart(direction_df).mark_line(order =False).encode( x ='Social_Domain', y ='Econ_Domain', color = alt.Color('PC direction', scale = alt.Scale(scheme ='dark2')))# combine with scattercentered_plot = (centered.properties(width =300, height =300) + mean_ctr + ax1 + ax2)(centered_plot + eigenbasis).configure_axis( labelFontSize =14, titleFontSize =16).configure_title( fontSize =16).configure_legend( labelFontSize =14, titleFontSize =16)
Where do these directions point relative to the scatter?
Geometry of PCA
Now scale the directions by the corresponding eigenvalues (plotting \(\lambda_1\mathbf{v}_1\) and \(\lambda_2\mathbf{v}_2\) instead of \(\mathbf{v}_1\) and \(\mathbf{v}_2\)).
So the total variation is the sum of the eigenvalues, and the variance of each PC is the corresponding eigenvalue.
We can therefore define the proportion of total variation explained by the \(j\)th principal component as:
\[
\frac{\lambda_j}{\sum_{j = 1}^p \lambda_j}
\]
This is sometimes also called the variance ratio for the \(j\)th principal component.
Quantifying variation capture/loss
So in our example, the variance ratios are:
# compute correlation mxr_mx = z_mx.transpose().dot(z_mx)/(len(z_mx) -1)# eigendecompositionr_eig = linalg.eig(r_mx.values)# store eigenvalues as real arrayeigenvalues = r_eig[0].real # variance ratioseigenvalues/eigenvalues.sum()
array([0.76574532, 0.23425468])
the first principal component captures 77% of total variation
the second captures 23% of total variation
Interpreting principal components
So we have obtained a single derived variable that captures 3/4 of total variation.
But what is the meaning of the derived variable? What does it represent in the context of the data?
The values of the first principal component (green ticks) are given by: \[
\text{PC1}_i = \mathbf{x}_i'\mathbf{v}_1 = 0.7071 \times\text{economic}_i + 0.7071 \times\text{social}_i
\]
So the principal component is a linear combination of the underlying variables.
the coefficients \((0.7071, 0.7071)\) are known as loadings
the values are known as principal component scores
In this case, the PC1 loadings are equal; so this principal component is simply the average of the social and economic indices.
In scikit-learn, one must preprocess the data by centering and scaling:
from sklearn.decomposition import PCA# center and scale dataz_mx = (x_mx - x_mx.mean())/x_mx.std()# compute principal componentspca = PCA(n_components =2)pca.fit(z_mx)
When the data are not standardized, the method is susceptible to problems of scale.
In our example, the economic index became more ‘important’, but this is only because it has a larger variance:
x_mx.cov()
Econ_Domain
Social_Domain
Econ_Domain
0.007428
0.001985
Social_Domain
0.001985
0.001878
So if the covariance (not correlation) matrix is decomposed, economic sustainability accounts for more of the total variation measure, because it dominates the variance-covariance matrix, but only because of scale.
Recall that this implementation requires centering and scaling the data first ‘by hand’.
from sklearn.decomposition import PCA# center and scalewdi_ctr = (wdi - wdi.mean())/wdi.std()# compute principal componentspca = PCA(31)pca.fit(wdi_ctr)
Variance ratios
Selecting the number of principal components to use is somewhat subjective, but always based on the variance ratios and their cumulative sum:
Code
# store proportion of variance explained as a dataframepcvars = pd.DataFrame({'Proportion of variance explained': pca.explained_variance_ratio_})# add component number as a new columnpcvars['Component'] = np.arange(1, 32)# add cumulative variance explained as a new columnpcvars['Cumulative variance explained'] = pcvars.iloc[:, 0].cumsum(axis =0)# encode component axis only as base layerbase = alt.Chart(pcvars).encode( x ='Component')# make a base layer for the proportion of variance explainedprop_var_base = base.encode( y = alt.Y('Proportion of variance explained', axis = alt.Axis(titleColor ='#57A44C')))# make a base layer for the cumulative variance explainedcum_var_base = base.encode( y = alt.Y('Cumulative variance explained', axis = alt.Axis(titleColor ='#5276A7')))# add points and lines to each base layerline = alt.Chart(pd.DataFrame({'Component': [2.5]})).mark_rule(opacity =0.3, color ='red').encode(x ='Component')prop_var = prop_var_base.mark_line(stroke ='#57A44C') + prop_var_base.mark_point(color ='#57A44C') + linecum_var = cum_var_base.mark_line() + cum_var_base.mark_point() + line# layer the layersvariance_plot = alt.layer(prop_var, cum_var).resolve_scale(y ='independent') variance_plot.properties(height =200, width =400).configure_axis( labelFontSize =14, titleFontSize =16)
In this case, the variance ratios drop off after 2 components. These first two capture about half of total variation in the data.
Loading plots
Examining the loadings graphically can help to interpret the components.
Code
# store the loadings as a data frame with appropriate namesloading_df = pd.DataFrame(pca.components_).transpose().rename( columns = {0: 'PC1', 1: 'PC2'}).loc[:, ['PC1', 'PC2']]# add a column with the taxon namesloading_df['indicator'] = wdi_ctr.columns.values# melt from wide to longloading_plot_df = loading_df.melt( id_vars ='indicator', var_name ='PC', value_name ='Loading')# create base layer with encodingbase = alt.Chart(loading_plot_df).encode( y = alt.X('indicator', title =''), x ='Loading', color ='PC')# store horizontal line at zerorule = alt.Chart(pd.DataFrame({'Loading': 0}, index = [0])).mark_rule().encode(x ='Loading', size = alt.value(2))# layer points + lines + rule to construct loading plotloading_plot = base.mark_point() + base.mark_line() + ruleloading_plot.properties(width =300, height =400).configure_axis( labelFontSize =14, titleFontSize =16)
Visualization
Finally, we might want to use the first two principal components to visualize the data.
Code
# project pcdata onto first two components; store as data frameprojected_data = pd.DataFrame(pca.fit_transform(wdi_ctr)).iloc[:, 0:2].rename(columns = {0: 'PC1', 1: 'PC2'})# add index and resetprojected_data.index = wdi_ctr.indexprojected_data = projected_data.reset_index()# append one of the original variablesprojected_data['gdppc'] = wdi.gdp_percapita.valuesprojected_data['pop'] = wdi.total_pop.values# base chartbase = alt.Chart(projected_data)# data scatterscatter = base.mark_point().encode( x = alt.X('PC1:Q', title ='Mortality'), y = alt.Y('PC2:Q', title ='Labor'), color = alt.Color('gdppc', bin= alt.Bin(maxbins =6), scale = alt.Scale(scheme ='blues'), title ='GDP per capita'), size = alt.Size('pop', scale = alt.Scale(type='sqrt'), title ='Population')).properties(width =400, height =400)# text labelslabel = projected_data.sort_values(by ='gdppc', ascending =False).head(4)text = alt.Chart(label).mark_text(align ='left', dx =3).encode( x = alt.X('PC1:Q', title ='Mortality'), y = alt.Y('PC2:Q', title ='Labor'), text ='country')(scatter + text).configure_axis( labelFontSize =14, titleFontSize =16)
Often it’s helpful to merge the principal components with the original data and apply visualization techniques you already know to search for interesting patterns.
Perspectives on PCA
Now that you know that a subcollection of principal components is usually selected, you have a sense that PCA involves projecting multivariate data onto a subspace.
There are two main perspectives on the meaning of this:
Low-rank approximation of the correlation structure
This is the perspective we’ve taken in this class
Latent regression or optimization problem
Find the axes that maximize variance of projected data
Other applications of PCA
PCA can also be used as a filtering technique for image data.
Noisy handwritten digits
Reconstruction from 12 PC’s computed from the pixel values.
Other applications of PCA
In a similar vein, it can be used as a compression technique.
Full-size images are roughly 3K pixels
Projecting pixel values onto 150 PC’s and then reconstructing the data from this subset yields a heavily compressed image